
Warum neuronale Kapselnetzwerke nicht skalieren
In den letzten Jahren haben tiefe Lernverfahren das maschinelle Lernen revolutioniert. Den Anfang dieser Revolution, im Jahr 2012, markiert der Artikel ImageNet Classification with Deep Convolutional Networks von Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton. In dem Artikel wird gezeigt, wie Convolutional Neural Networks (CNNs) andere zur damaligen Zeit noch populäre Lernverfahren im Klassifizieren von Bildern dramatisch übertreffen können. Einer der Autoren, Turing Award Gewinner Geoffrey Hinton, war nicht nur glücklich über diesen Erfolg, der vergessen machen kann, dass CNNs viele Probleme haben. In einem Vortrag von 2014 nennt er die folgenden Probleme:
- CNNs benötigen viele Trainingsdaten
- CNNs sind nicht invariant unter einfachen geometrischen Transformationen wie kleinen Verschiebungen und Drehungen
- CNNs sind auch nicht invariant unter einer Änderung der Blickrichtung
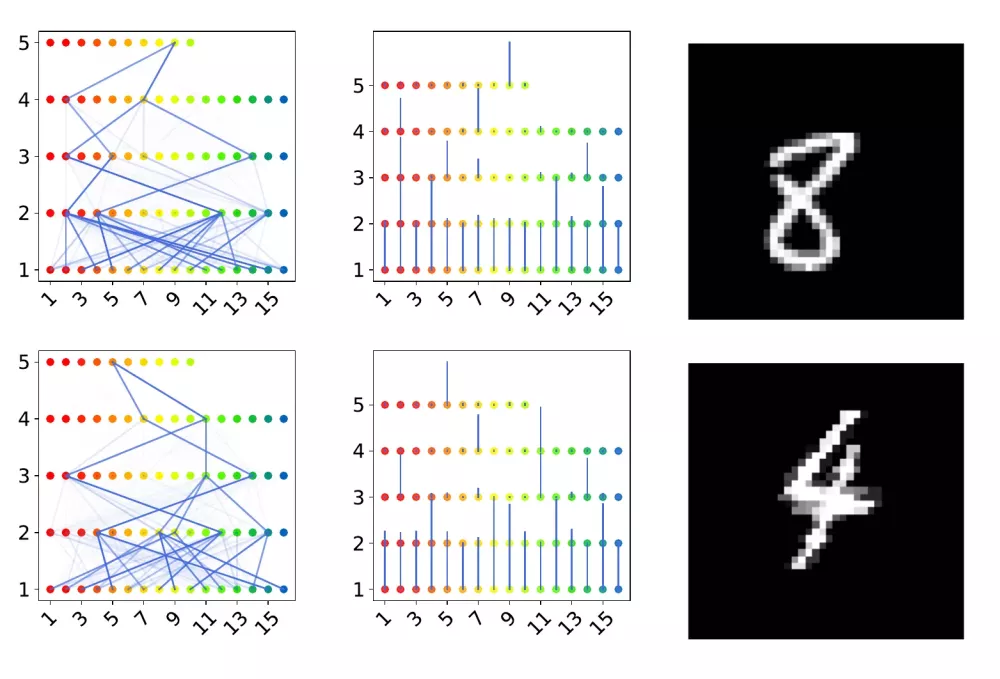
Hinton schlägt mit Capsule Neural Networks (CapsNets) auch eine durch Neurowissenschaften inspirierte Alternative zu CNNs vor, die die Probleme nicht haben soll. Hinton geht davon aus, dass das Gehirn über Module verfügt, die er als Capsules (Kapseln) bezeichnet. Verschiedene Capsules können verschiedene Arten von visuellen Reizen verarbeiten. So könnte es beispielsweise eine Capsule für Gesichter und eine andere für Häuser geben. Das Gehirn scheint über einen Mechanismus zu verfügen, der visuelle Informationen auf niedriger Ebene an die Kapsel weiterleitet, die am besten geeignet ist, sie zu verarbeiten. Capsules für Augen, Nasen oder Münder sollten ihre Information also an die Capsule für Gesichter weiterleiten und Capsules für Fenster oder Türen sollten ihre Information an die Capsule für Häuser weiterleiten. Die Hierarchisierung von Capsules wird auch als Parse-Tree (Syntaxbaum) bezeichnet.
CapsNets waren zunächst ein theoretisches Konzept, das sehr positiv aufgenommen wurde. In seinem Bestseller A Thousand Brains: A New Theory of Intelligence schreibt Jeff Hawkins “Capsules promise dramatic improvements in neural networks”. 2017 haben Sara Sabour, Nicolas Frosst und Geoffrey Hinton dann eine konkrete Implementierung von CapsNets vorgestellt. Erste Experimente mit dieser Implementierung auf kleinen Bilddatensätzen waren so vielversprechend, dass diese Arbeit mittlerweile schon mehr als viertausendmal in Anwendungen und Erweiterungen zitiert wird. Es schien so, dass CapsNets die drei von Hinton aufgezeigten Probleme von CNNs tatsächlich vermeiden können. Im Laufe der Zeit kamen aber Zweifel auf, ob der Ansatz auch auf größere, komplexere Datensätze skaliert. Das war der Anlass für uns, CapsNets systematisch zu untersuchen.
Im Kern unserer experimentellen Untersuchung stehen zwei zentrale Annahmen:
- Die von CapsNets gefundenen Capsules repräsentieren ausgezeichnete visuelle Einheiten, die invariant unter einfachen geometrischen Transformationen und unter Änderung der Blickrichtung sind
- Die Einheiten werden in einem sinnvollen Syntaxbaum organisiert
Das Ergebnis unserer umfangreichen Experimente ist, dass beide Annahmen nicht aufrechterhalten werden können. Unsere experimentellen Ergebnisse werden durch eine mathematische Analyse unterstützt, die ein grundlegendes Problem in dem Modell von CapsNets aufdeckt. Mathematisch ausgedrückt gibt es einen verschwindenden Gradienten, was dazu führt, dass nur sehr wenige Capsules zu dem übergeordneten Kontext beitragen können. Über CapsNets kann daher kein größerer Zusammenhang gelernt werden. Ein Weltverständnis, wie das menschliche Gehirn es aufbaut, kann nicht entstehen.
Veröffentlichung: M. Mitterreiter, M. Koch, J. Giesen und S. Laue. Why Capsule Neural Networks Do Not Scale: Challenging the Dynamic Parse-Tree Assumption. Proceedings of the 37th AAAI Conference on Artificial Intelligence (AAAI 2023)
Mehr zu dem Thema erfahren Sie bei unserem nächsten DAS TechTalks-Event am 22.06.2023. Hier anmelden!