
Why Capsule Neural Networks Do Not Scale
In recent years, deep learning techniques have revolutionized machine learning. The beginning of this revolution, in 2012, was marked by the article ImageNet Classification with Deep Convolutional Networks by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton. The article demonstrates how Convolutional Neural Networks (CNNs) can dramatically outperform other learning methods still popular at the time in classifying images. One of the authors, Turing Award winner Geoffrey Hinton, was not all happy about this success, which can make you forget that CNNs have many problems. In a 2014 talk, he cites the following problems:
- CNNs require a lot of training data
- CNNs are not invariant under simple geometric transformations such as small displacements and rotations
- CNNs are also not invariant under a change in viewing direction
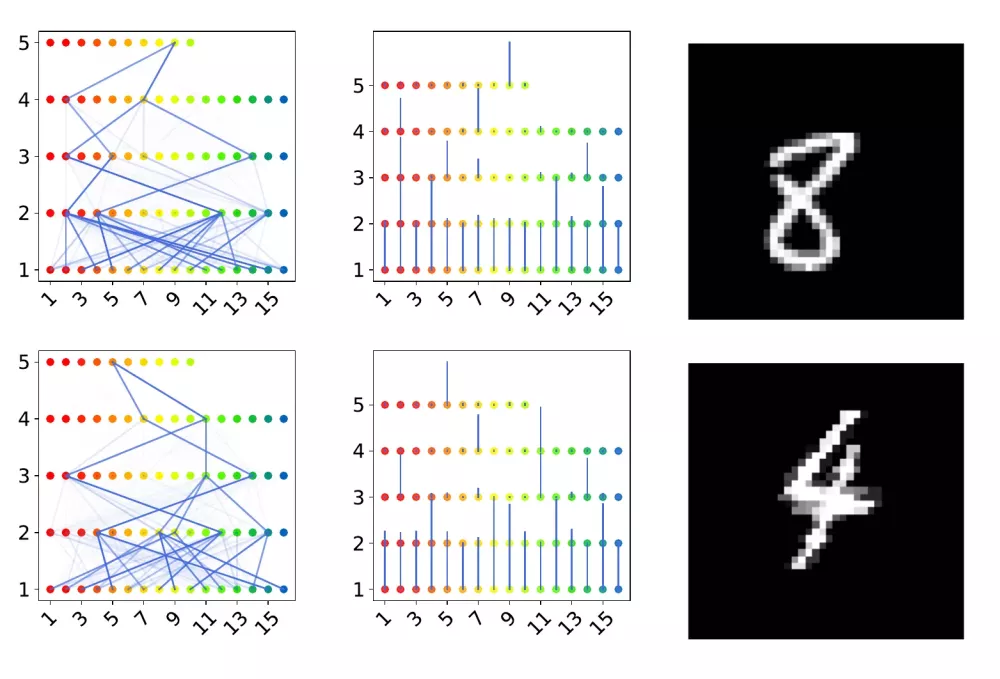
Hinton also proposes Capsule Neural Networks (CapsNets), a neuroscience-inspired alternative to CNNs that is said not to have the problems. Hinton assumes that the brain has modules that he calls Capsules. Different Capsules can process different types of visual stimuli. For example, there might be one Capsule for faces and another for houses. The brain seems to have a mechanism that relays low-level visual information to the Capsule that is best suited to process it. Capsules for eyes, noses, or mouths should thus pass their information to the Capsule for faces, and Capsules for windows or doors should pass their information to the Capsule for houses. The hierarchy of Capsules is also called a parse tree.
CapsNets were initially a theoretical concept that was very well received. In his bestseller A Thousand Brains: A New Theory of Intelligence, Jeff Hawkins writes “Capsules promise dramatic improvements in neural networks.” Then in 2017, Sara Sabour, Nicolas Frosst, and Geoffrey Hinton presented a concrete implementation of CapsNets. Initial experiments with this implementation on small image datasets were so promising that this work has now been cited more than four thousand times in applications and extensions. It seemed that CapsNets could indeed avoid the three problems of CNNs pointed out by Hinton. But as time went on, doubts arose as to whether the approach would scale to larger, more complex data sets. This prompted us to systematically investigate CapsNets.
At the core of our experimental investigation are two central assumptions:
- The capsules found by CapsNets represent excellent visual units that are invariant under simple geometric transformations and under change of gaze direction
- The units are organized in a meaningful syntax tree
The result of our extensive experiments is that neither assumption can be sustained. Our experimental results are also supported by a mathematical analysis that reveals a fundamental problem in the CapsNets model. In mathematical terms, there is the problem of a vanishing gradient revealing that what results in very few Capsules at higher hierarchical levels can be active to contribute to the higher-level context. Therefore, no larger context can be learned via CapsNets. An understanding of the world, as the human brain builds it, cannot emerge.
Publication: M. Mitterreiter, M. Koch, J. Giesen, and S. Laue. Why Capsule Neural Networks Do Not Scale: Challenging the Dynamic Parse-Tree Assumption. Proceedings of the 37th AAAI Conference on Artificial Intelligence (AAAI 2023).